Hi @Nick
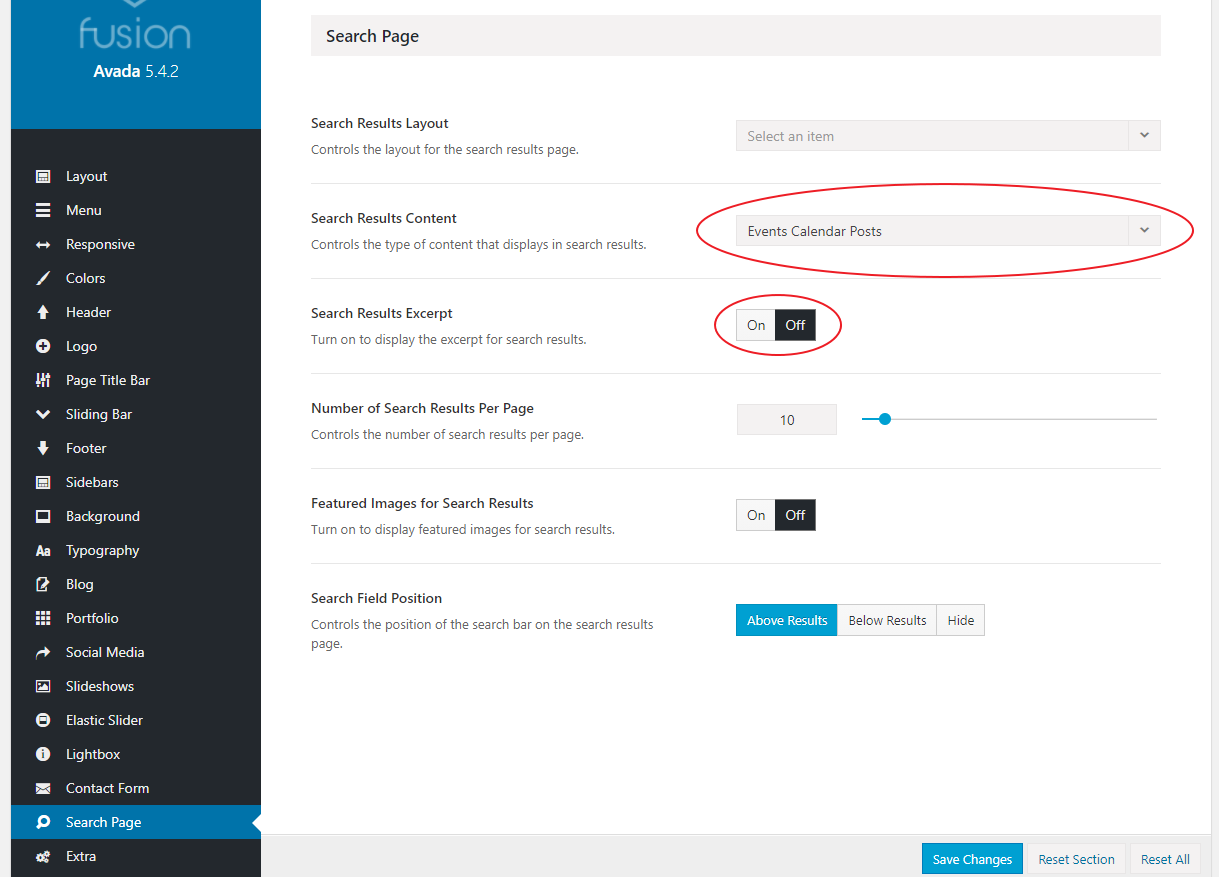
It seems to be you're using the Avada theme, which has known conflict with the Smart Excerpts algorithm. Please consider checking this topic to find the proper solution.
Renaming Media titles would be the good and clean solution, however, we still could try to extract magazine titles from the PDF. The PDF format is a bad way to store layout data because on the extraction phase it normally loses all the structure, so extracting a part of text could be not a simple and straightforward task. But we can try. Could you send me one of two files just to check if we can get a title from the extracted text or not?
Additionally, you can try to open the Edit Attachment page for those files in your WP admin and find the "WPFTS Extracted Text" window there. The magazine title should be somewhere in the first row of text. If so - we can build the algorithm which will extract this header.
As for opening the file exactly on the page where the text was found - we are working on this function at the moment, an alpha version for testing will be ready very soon. We'll let you know as soon as it's ready.
Please let me know if Avada theme fix works for you.
Thank you!
![E20201017-224229-001[1].png](/forum/assets/uploads/files/1602962173729-e20201017-224229-001-1.png)
